Addy Osmani —《理解债:AI 生成代码的隐藏成本》(全文)
原文: https://addyosmani.com/blog/comprehension-debt/ 作者: Addy Osmani(Google 软件工程师,负责 Google Cloud / Gemini;《Learning JavaScript Design Patterns》作者) 原文发布日期: 2026 年 3 月 14 日 本译版定位: 完整逐段翻译 + 译注。配套精读:Addy Osmani 三连
译者前言
这篇是 Addy Osmani 三连发里最锋利、对中文工程师最该重读的一篇。如果说 Factory Model 描述的是 AI 编程时代的”乐观蓝图”——你将编排数十个 agent,杠杆放大几十倍——那么 Comprehension Debt 就是这张蓝图的”暗面账单”:你的 velocity 指标会一片绿色,但一个看不见的债务正在飞速累积。
为什么这一篇值得读全文?三个理由:
第一,“comprehension debt”是一个新概念,但它指的是中文圈每个 AI 编程团队都已经踩到的坑。开发者跑 Cursor / Copilot / Claude Code 跑得很爽,功能合得很快,直到某天有人问”这个模块为什么这么设计?“,全队没人答得上来——这就是理解债。Addy 给这件事取了一个准确的名字,以及一套衡量框架。给一件你已经在踩的坑命名,本身就是一种思考工具升级。
第二,它精确解构了”测试 + spec”两条常见出路的失败模式。中文圈关于”AI 编程怎么保证质量”的讨论,主流方案要么是”加测试覆盖”,要么是”前期写详细 spec”。Addy 这一篇直接把这两条路的天花板一一打掉:测试不能给”你没想到要测的行为”提供保护;详细 spec 写到能替代审阅的程度,本质就等于把程序写了一遍。这是非常硬核的”反直觉论证”,中文圈类似深度的分析非常少。
第三,它给出了一个组织级别的预警:DORA 指标 / velocity / PR 数都在涨,但衡量系统再也不能反映”实际理解程度”。这对管理者尤其有用——如果你在做工程团队管理,这一篇是 2026 年的必读。文章结尾点出”监管视野”已经在收紧,医疗 / 金融 / 政务系统出事时”AI 写的、我们没完全看”不会成为有效辩护——这是给整个行业的提醒。
理解债——AI 生成代码的隐藏成本
2026 年 3 月 14 日
原文:Comprehension debt is the hidden cost to human intelligence and memory resulting from excessive reliance on AI and automation. For engineers, it applies most to agentic engineering.
理解债(Comprehension debt)是过度依赖 AI 和自动化所导致的、对人类智识与记忆的隐性成本。对工程师而言,它最典型地体现在 agentic engineering(智能体工程)中。
🟢 译者注:Comprehension debt = 理解债。这是和”技术债(technical debt)“对仗的新概念。Cognitive debt 是同一意思的另一种叫法,源自 MIT Media Lab 的论文。
原文:There’s a cost that doesn’t show up in your velocity metrics when teams go deep on AI coding tools. Especially when its tedious to review all the code the AI generates. This cost accumulates steadily, and eventually it has to be paid - with interest. It’s called comprehension debt or cognitive debt.
当团队大幅深入使用 AI 编程工具时,有一种成本不会出现在你的 velocity 指标里——尤其是当审阅 AI 生成的所有代码变得繁琐时。这种成本稳定地累积,最终必须连本带利地偿还。它叫理解债或者认知债(cognitive debt)。
原文:Comprehension debt is the growing gap between how much code exists in your system and how much of it any human being genuinely understands.
理解债,是你系统中存在的代码量,与”任何一个人类真正理解的代码量”之间的不断扩大的差距。
原文:Unlike technical debt, which announces itself through mounting friction - slow builds, tangled dependencies, the creeping dread every time you touch that one module - comprehension debt breeds false confidence. The codebase looks clean. The tests are green. The reckoning arrives quietly, usually at the worst possible moment.
不同于技术债——它会通过日益增加的摩擦自我宣告:慢吞吞的构建、纠缠的依赖、每次碰那个模块时悄然爬上脊背的恐惧——理解债却滋生虚假的信心。代码库看上去很干净,测试一片绿色。清算时刻悄无声息地到来,通常出现在最糟糕的时机。
原文:Margaret-Anne Storey’s describes a student team that hit this wall in week seven: they could no longer make simple changes without breaking something unexpected. The real problem wasn’t messy code. It was that no one on the team could explain why design decisions had been made or how different parts of the system were supposed to work together. The theory of the system had evaporated.
Margaret-Anne Storey 描述过一支学生团队在第 7 周撞上这堵墙:他们再也没法做简单的改动,而不在某处弄坏点意料之外的东西。真正的问题不是代码乱,而是团队里没有人能解释为什么当初做了那些设计决策、系统的不同部分应该如何协同工作。系统的”理论”蒸发了。
🟢 译者注:Margaret-Anne Storey 是维多利亚大学的软件工程教授,长期研究开发者如何理解大型代码库,是这个领域的权威。
原文:That’s comprehension debt compounding in real time.
这就是理解债在实时复利。
原文:I’ve read Hacker News threads that captured engineers genuinely wrestling with the structural version of this problem - not the familiar optimism versus skepticism binary, but a field trying to figure out what rigor actually looks like when the bottleneck has moved.
我读过一些 Hacker News 上的讨论,里面工程师们真在认真较劲这个问题的结构化版本——不是熟悉的”乐观派 vs 怀疑派”二元对立,而是一个领域在试图搞清楚:当瓶颈已经位移之后,所谓的”严谨”到底应该长什么样。
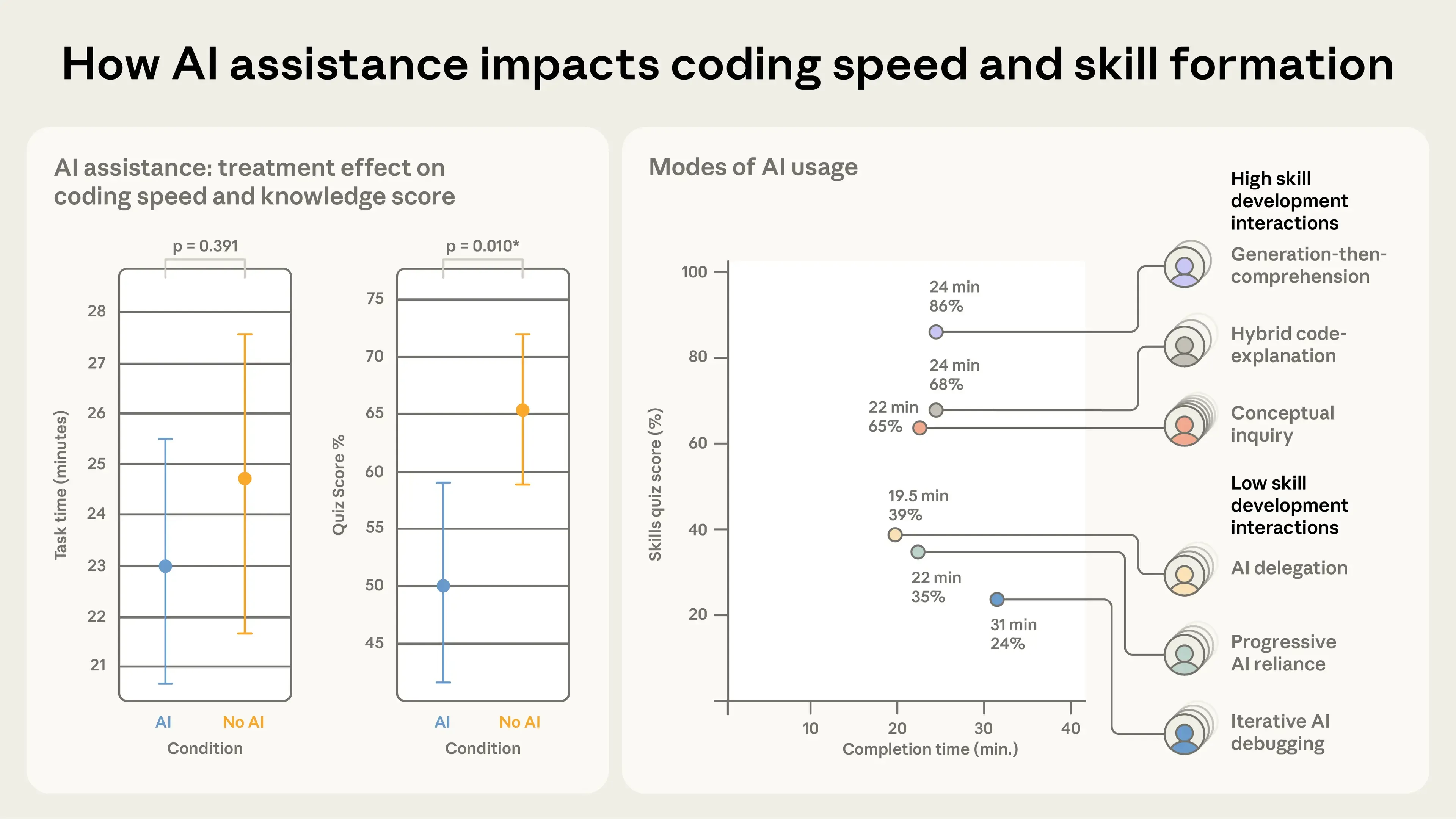
原文:A recent Anthropic study titled “How AI Impacts Skill Formation” highlighted the potential downsides of over-reliance on AI coding assistants. In a randomized controlled trial with 52 software engineers learning a newlibrary, participants who used AI assistance completed the task in roughly the same time as the control group but scored 17% lower on a follow-up comprehension quiz (50% vs. 67%). The largest declines occurred in debugging, with smaller but still significant drops in conceptual understanding and code reading. The researchers emphasize that passive delegation (“just make it work”) impairs skill development far more than active, question-driven use of AI. The full paper is available arXiv: https://arxiv.org/abs/2601.20245.
Anthropic 最近一项题为《AI 如何影响技能形成》的研究,凸显了过度依赖 AI 编程助手的潜在风险。在一项面向 52 名学习一个新库的软件工程师的随机对照试验中,使用 AI 辅助的参与者完成任务用时与对照组相近,但在事后理解力测验中得分低 17%(50% vs. 67%)。下降最大的是 debugging 项,概念理解和代码阅读项也有较小但仍显著的下降。研究者强调:被动委托(“反正把它跑起来”式)对技能发展的损害,远大于主动的、以提问为驱动的 AI 使用方式。完整论文见 arXiv:https://arxiv.org/abs/2601.20245。
🟢 译者注:这一段的关键词是 “passive delegation vs. active inquiry”。也就是:同样用 AI,问 AI “帮我写出来”和问 AI “这是为什么、有哪些权衡”,对你的技能影响是反向的。这不是”用不用 AI”的问题,是”怎么用”的问题。
这里有一个速度不对称问题
原文:AI generates code far faster than humans can evaluate it. That sounds obvious, but the implications are easy to underestimate.
AI 生成代码的速度远快于人类评估代码的速度。这听上去很显然,但它的含义很容易被低估。
原文:When a developer on your team writes code, the human review process has always been a bottleneck - but a productive and educational one. Reading their PR forces comprehension. It surfaces hidden assumptions, catches design decisions that conflict with how the system was architected six months ago, and distributes knowledge about what the codebase actually does across the people responsible for maintaining it.
当团队里一个开发者写代码时,人类审阅过程一直是一个瓶颈——但这是一个高产且具有教育意义的瓶颈。读他们的 PR 强迫你去理解;它把暗藏的假设暴露出来,抓住与”6 个月前系统是怎么设计的”冲突的决策,并把”代码库到底在做什么”这个知识,分发到所有负责维护它的人头上。
原文:AI-generated code breaks that feedback loop. The volume is too high. The output is syntactically clean, often well-formatted, superficially correct - precisely the signals that historically triggered merge confidence. But surface correctness is not systemic correctness. The codebase looks healthy while comprehension quietly hollows out underneath it.
AI 生成的代码打破了这个反馈循环。体量太大。输出在语法上干净、格式通常很好、表面上正确——这些恰恰是历史上让人产生”可以合”的信号。但表面正确性 ≠ 系统正确性。代码库看上去健康,而理解力在底下悄悄被掏空。
原文:I read one engineer say that the bottleneck has always been a competent developer understanding the project. AI doesn’t change that constraint. It creates the illusion you’ve escaped it.
我读到一位工程师说:瓶颈一直都是”有能力的开发者真的理解这个项目”。AI 没改变这个约束,它制造的是”你已经摆脱了这个约束”的错觉。
原文:And the inversion is sharper than it looks. When code was expensive to produce, senior engineers could review faster than junior engineers could write. AI flips this: a junior engineer can now generate code faster than a senior engineer can critically audit it. The rate-limiting factor that kept review meaningful has been removed. What used to be a quality gate is now a throughput problem.
而这种反转比看上去更尖锐。当代码生产昂贵时,senior 工程师 review 的速度比 junior 工程师写代码的速度更快。AI 把这件事翻过来了:一个 junior 工程师现在能生成代码的速度,快过一个 senior 工程师批判性审阅的速度。让审阅有意义的那个速率限制因子,被移除了。过去是质量闸门的东西,现在变成了吞吐量问题。
🟢 译者注:这一段是这篇里的核心论点之一,也是中文圈对”AI 编程团队管理”理解最不到位的一点。“senior review 比 junior write 快”——这是过去 30 年代码 review 制度建立的物理基础;一旦这个基础被 AI 打破,整个 review 制度的设计前提都需要重写。
我爱测试,但它不是完整答案
原文:The instinct to lean harder on deterministic verification - unit tests, integration tests, static analysis, linters, formatters - is understandable. I do this a lot in projects heavily leaning on AI coding agents. Automate your way out of the review bottleneck. Let machines check machines.
人们的本能反应是更用力地依靠确定性验证——单元测试、集成测试、静态分析、linter、formatter。这种倾向可以理解,我自己在重度依赖 AI 编程 agent 的项目里也大量这么做。用自动化的方式把自己挤出审阅瓶颈,让机器去查机器。
原文:This helps. It has a hard ceiling.
这有用,但它有一道硬天花板。
原文:A test suite capable of covering all observable behavior would, in many cases, be more complex than the code it validates. Complexity you can’t reason about doesn’t provide safety though. And beneath that is a more fundamental problem: you can’t write a test for behavior you haven’t thought to specify.
一套能覆盖所有可观察行为的测试套件,很多情况下会比它验证的代码本身还复杂。你无法推理的复杂度,并不能提供安全感。在这之下还有一个更根本的问题——你没法为”你从来没想到要规定的行为”写测试。
原文:Nobody writes a test asserting that dragged items shouldn’t turn completely transparent. Of course they didn’t. That possibility never occurred to them. That’s exactly the class of failure that slips through, not because the test suite was poorly written, but because no one thought to look there.
没有人会去写一个断言”被拖拽的元素不应该变得完全透明”的测试。当然没人写——这种可能性从未出现在他们脑中。而这正是会溜过去的那一类失败——不是因为测试套件写得差,而是因为没有人想过要去那里看。
🟢 译者注:这个具体例子是 Addy 的伏笔——“被拖拽的元素完全透明”是 2024 年某真实 bug 的一个常见示例:UI 上看起来”东西不见了”,但其实只是 opacity:0,鼠标交互全在,但用户找不到。这类 case 没有任何 spec 和测试会主动覆盖。
原文:There’s also a specific failure mode worth naming. When an AI changes implementation behavior and updates hundreds of test cases to match the new behavior, the question shifts from “is this code correct?” to “were all those test changes necessary, and do I have enough coverage to catch what I’m not thinking about?” Tests cannot answer that question. Only comprehension can.
还有一种特定的失败模式值得点名:当 AI 改变了实现行为,并把数百条测试用例更新成匹配新行为时,问题从”这段代码是对的吗”变成了——“那些测试改动都是必要的吗?我的覆盖率够不够抓住我没想到的东西?”测试无法回答这个问题。只有理解力可以。
原文:The data is starting to back this up. Research suggests that developers using AI for code generation delegation score below 40% on comprehension tests, while developers using AI for conceptual inquiry - asking questions, exploring tradeoffs - score above 65%. The tool doesn’t destroy understanding. How you use it does.
数据开始支持这一点。研究显示:用 AI 做”代码生成委托”的开发者,在理解力测试上得分低于 40%;而用 AI 做”概念询问”——提问、探索权衡——的开发者,得分高于 65%。工具本身不会摧毁理解,你怎么用它会。
原文:Tests are necessary. They are not sufficient.
测试是必要的,它们不是充分的。
押注 spec,但 spec 也不是全部故事
原文:A common proposed solution: write a detailed natural language spec first. Include it in the PR. Review the spec, not the code. Trust that the AI faithfully translated intent into implementation.
一个常见的提议方案是:先写一份详细的自然语言 spec,把它附在 PR 里,审 spec 而不是审代码,相信 AI 忠实地把意图翻译成了实现。
原文:This is appealing in the same way Waterfall methodology was once appealing. Rigorously define the problem first, then execute. Clean separation of concerns.
这个想法的吸引力,和瀑布(Waterfall)方法论曾经的吸引力是同一种——先严格定义问题,再去执行。关注点分离得很干净。
🟢 译者注:Waterfall(瀑布模型)是 1970 年代主流的软件开发流程:需求 → 设计 → 实现 → 测试 → 部署,严格按顺序往下走。后来被 Agile / Scrum 等迭代方法论取代——核心原因正是 Addy 下面要论证的:复杂系统的需求无法在前期被完整规定。
原文:The problem is that translating a spec to working code involves an enormous number of implicit decisions - edge cases, data structures, error handling, performance tradeoffs, interaction patterns - that no spec ever fully captures. Two engineers implementing the same spec will produce systems with many observable behavioral differences. Neither implementation is wrong. They’re just different. And many of those differences will eventually matter to users in ways nobody anticipated.
问题是,把 spec 翻译成可工作代码,会涉及大量隐性决策——边界 case、数据结构、错误处理、性能权衡、交互模式——这些没有任何 spec 能完整捕获。两个工程师实现同一份 spec,会产出在很多可观察行为上有差别的系统。两份实现都没错,它们只是不同。而其中很多差异,最终会以”没人预料到”的方式对用户产生影响。
原文:There’s another possibility with detailed specs worth calling out: a spec detailed enough to fully describe a program is more or less the program, just written in a non-executable language. The organizational cost of writing specs thorough enough to substitute for review may well exceed the productivity gains from using AI to execute them. And you still haven’t reviewed what was actually produced.
关于”详细 spec”还有一种可能性值得点出:一份详细到能完整描述程序的 spec,差不多就是程序本身,只不过是用一种不可执行的语言写的。把 spec 写到详细到能替代审阅的程度,所付出的组织成本,很可能超过用 AI 来执行 spec 所获得的生产力增益。而你仍然没有审阅”真正被产出”的那个东西。
原文:The deeper issue is that there is often no correct spec. Requirements emerge through building. Edge cases reveal themselves through use. The assumption that you can fully specify a non-trivial system before building it has been tested repeatedly and found wanting. AI doesn’t change this. It just adds a new layer of implicit decisions made without human deliberation.
更深的问题是:很多时候根本不存在”正确”的 spec。需求是在构建过程中浮现的,边界 case 是在使用中暴露的。“你能在构建一个非平凡系统之前就完整规定它”——这个假设已经被反复测试过,反复被证明站不住。AI 没有改变这一点,它只是又叠加了一层”未经人类深思的隐性决策”。
从历史中学习
原文:Decades of managing software quality across distributed teams with varying context and communication bandwidth has produced real, tested practices. Those don’t evaporate because the team member is now a model.
几十年来,在跨分布式团队、且这些团队上下文与沟通带宽各不相同的情况下管理软件质量,已经沉淀出了真实有效、经历过检验的实践。这些实践不会因为团队成员变成了一个模型而蒸发掉。
原文:What changes with AI is cost (dramatically lower), speed (dramatically higher), and interpersonal management overhead (essentially zero). What doesn’t change is the need for someone with deep system context to maintain coherent understanding of what the codebase is actually doing and why.
AI 改变的是:成本(大幅下降)、速度(大幅上升)、人际管理 overhead(几乎归零)。没改变的是:仍然需要一个对系统有深刻上下文的人,来维持对”代码库到底在做什么、为什么”的连贯理解。
原文:This is the uncomfortable redistribution that comprehension debt forces.
这就是理解债强行带来的、令人不适的再分配。
原文:As AI volume goes up, the engineer who truly understands the system becomes more valuable, not less. The ability to look at a diff and immediately know which behaviors are load-bearing. To remember why that architectural decision got made under pressure eight months ago.
随着 AI 产出量上升,真正理解系统的工程师变得更有价值,而不是更没价值。看一眼 diff 立刻知道哪些行为是承重的(load-bearing) 这种能力。记得 8 个月前那个在压力下做的架构决策为什么是那样,这种能力。
🟢 译者注:“load-bearing”原意是建筑里的承重墙——拆掉就垮。这里指代码里那些”看起来普通但删了系统就崩”的关键行为。这是一类极难自动化识别的知识。
原文:To tell the difference between a refactor that’s safe and one that’s quietly shifting something users depend on. That skill becomes the scarce resource the whole system depends on.
辨认”安全的重构”和”悄悄改变了用户依赖的某种行为的重构”之间的差别——这种技能,会成为整个系统所依赖的稀缺资源。
这里还有一个度量缺口
原文:The reason comprehension debt is so dangerous is that nothing in your current measurement system captures it.
理解债之所以如此危险,是因为你当前度量系统中,没有任何一项能捕获它。
原文:Velocity metrics look immaculate. DORA metrics hold steady. PR counts are up. Code coverage is green.
Velocity 指标看起来完美无瑕。DORA 指标稳如磐石。PR 数量上升。代码覆盖率一片绿。
🟢 译者注:DORA(DevOps Research and Assessment)是 Google 在 2014 年提出的、衡量软件交付效能的标准框架,核心 4 个指标是:部署频率(Deployment Frequency)、变更前置时间(Lead Time for Changes)、变更失败率(Change Failure Rate)、平均恢复时间(MTTR)。中文圈大厂普遍使用。
原文:Performance calibration committees see velocity improvements. They cannot see comprehension deficits, because no artifact of how organizations measure output captures that dimension. The incentive structure optimizes correctly for what it measures. What it measures no longer captures what matters.
绩效评定委员会看到的是 velocity 提升。它们看不到理解力赤字,因为组织衡量产出的所有工件,都没有捕获那个维度。激励结构对它所衡量的东西做了正确的优化——但它所衡量的东西,已经不再捕获真正重要的东西了。
原文:This is what makes comprehension debt more insidious than technical debt. Technical debt is usually a conscious tradeoff - you chose the shortcut, you know roughly where it lives, you can schedule the paydown. Comprehension debt accumulates invisibly, often without anyone making a deliberate decision to let it. It’s the aggregate of hundreds of reviews where the code looked fine and the tests were passing and there was another PR in the queue.
这就是为什么理解债比技术债更阴险。技术债通常是一次有意识的权衡——你选了捷径,你大致知道它在哪、你能安排时间还掉。理解债则是隐形累积的,通常没有任何人做过”允许它累积”的明确决定。它是数百次”代码看上去还行、测试通过、队列里还有下一个 PR”的审阅之和。
原文:The organizational assumption that reviewed code is understood code no longer holds. Engineers approved code they didn’t fully understand, which now carries implicit endorsement. The liability has been distributed without anyone noticing.
组织里那个”审阅过的代码就是被理解的代码”的假设,不再成立。工程师批准了他们没有完全理解的代码,而这份代码现在已经带有了隐性的背书。责任已经被分发出去,没有人注意到。
🟢 译者注:这一段对中文大厂场景非常贴切:中文圈 PR review 的”已 approve”原本默认含义是”我看过、我理解、我背书”;如果 AI 时代这个默认含义还沿用,出事时所有 approver 都自动背责——但他们都没真正理解。这是一个非常隐蔽的”组织风险”。
监管视野比看上去更近
原文:Every industry that moved too fast eventually attracted regulation. Tech has been unusually insulated from that dynamic, partly because software failures are often recoverable, and partly because the industry has moved faster than regulators could follow.
任何动作太快的行业,最终都会引来监管。科技行业一直异常地与这个规律绝缘——一部分因为软件故障通常是可恢复的,一部分因为这个行业的速度比监管者跟得上的速度更快。
原文:That window is closing. When AI-generated code is running in healthcare systems, financial infrastructure, and government services, “the AI wrote it and we didn’t fully review it” will not hold up in a post-incident report when lives or significant assets are at stake.
这扇窗户正在关上。当 AI 生成的代码运行在医疗系统、金融基础设施、政府服务里时,“AI 写的、我们没有完全审”这种说法,在事关生命或重大资产的事故报告里,是站不住的。
原文:Teams building comprehension discipline now - treating genuine understanding, not just passing tests, as non-negotiable - will be better positioned when that reckoning arrives than teams that optimized purely for merge velocity.
现在就开始建立理解力纪律——把”真正的理解”而非”测试通过”作为不可妥协的硬约束——的团队,当那次清算到来时,会比那些纯粹为合并速度优化的团队站得更稳。
理解债到底要求什么
原文:The right question for now isn’t “how do we generate more code?” It’s “how do we actually understand more of what we’re shipping?” so we can make sure our users get a consistently high quality experience.
当下正确的问题,不是”我们怎么生成更多代码”,而是”我们怎么真正理解更多我们交付的东西”——这样才能保证用户得到持续高质量的体验。
原文:That reframe has practical consequences. It means being ruthlessly explicit about what a change is supposed to do before it’s written. It means treating verification not as an afterthought but as a structural constraint. It means maintaining the system-level mental model that lets you catch AI mistakes at architectural scale rather than line-by-line. And it means being honest about the difference between “the tests passed” and “I understand what this does and why.”
这种重新表述会带来实际的后果:
- 在改动被写出来之前,无情地把”它应该做什么”明确化;
- 把 verification(验证)当作结构性约束,而不是事后的补丁;
- 维持一个系统级别的心智模型,让你能在架构尺度——而不是逐行尺度——抓住 AI 的错误;
- 诚实地面对”测试通过了”和”我理解这个做什么、以及为什么”之间的差别。
原文:Making code cheap to generate doesn’t make understanding cheap to skip. The comprehension work is the job.
让代码变得生成成本低,并不会让”跳过理解”也变得成本低。理解工作,本身就是工作。
原文:AI handles the translation. But someone still has to understand what was produced, why it was produced that way, and whether those implicit decisions were the right ones - or you’re just deferring a bill that will eventually come due in full.
AI 负责翻译。但仍然必须有人理解被产出的是什么、为什么以那种方式被产出、那些隐性决策是不是对的——否则,你只是在把一笔账往后推,这笔账迟早会全额到期。
原文:You will pay for comprehension sooner or later. The debt accrues interest rapidly.
你迟早要为理解力付钱。这笔债的利息累积得很快。
进一步阅读(其他视角)
译者总评
5 个 takeaway,2026 中文工程师 / 工程经理最该带走的:
-
“理解债”是一个比”技术债”更隐蔽、更危险的新概念。技术债是显性的、有意识的权衡;理解债是无意识累积的、没有任何人做过”允许它累积”的决定。给一件你已经在踩的坑命名,本身就是思考工具升级——以后团队里讨论”AI 写出来的代码到底要不要全审”,可以直接用这个词。
-
“测试 + spec”两条出路都有硬天花板:测试不能给”你没想过要规定的行为”提供保护;spec 写到能替代审阅的程度,本质上等于把程序写了一遍,组织成本超过收益。这比”加测试覆盖率""推 PRD 评审”这种朴素方案要冷静得多。中文圈如果还在用这两条路对抗 AI 生成失控,可以暂停一下重新思考。
-
核心反转:“junior write 速度 > senior review 速度”打破了 30 年代码审阅制度的物理基础。中文大厂 PR review 制度的设计前提是”senior 比 junior 快”,一旦这个前提被 AI 颠覆,整个 review 制度需要重新设计——这不是”加 reviewer 数量”能解决的。
-
DORA / velocity / PR 数 / 代码覆盖率,这套度量在 AI 时代失灵了。“组织默认 reviewed code = understood code”这一假设不再成立——出事时责任已经隐性分发但无人察觉。如果你在做工程团队管理,理解力指标是 2026—2027 必须建立的新一代度量维度。具体怎么测?目前没有标准答案,这是 Addy 留给整个行业的问题。
-
“AI 写的、没完全审”在医疗/金融/政务出事时不是辩护词。Addy 这一句是给整个行业的警告——监管视野正在收紧。中文圈做政务 / 金融 / 医疗系统的团队,从现在开始建立”comprehension-first”流程,在监管浪潮到来前已经合规化,会比 velocity 党有结构性优势。
🔗 调研来源
- 原文: https://addyosmani.com/blog/comprehension-debt/(2026-03-14)
- 配套精读: Addy Osmani 三连
- 关联阅读: Factory Model(全文)
- 关联阅读: Anthropic “How AI Impacts Skill Formation” + arXiv:2601.20245
- 关联阅读: Margaret-Anne Storey “On Cognitive Debt”
- 关联阅读: MIT Media Lab “Your Brain on ChatGPT”
- 关联阅读: Simon Willison “On Cognitive Debt”
- 关联阅读: Latent Space “How to Kill the Code Review”
📝 配套精读 + 译者点评:Addy Osmani 三连:Factory Model / Comprehension Debt / Harness Engineering