Addy Osmani —《长跑 Agent》(全文)
原文: https://addyosmani.com/blog/long-running-agents/ 作者: Addy Osmani(Google Director, Cloud AI / Gemini) 发表日期: 2026 年 4 月 28 日 本译版定位: 完整逐段翻译 + 译注。配套精读:Addy Osmani 三连
译者前言
这是 Addy Osmani 三连里最务实、信息密度最高的一篇 —— 也是真正面向 staff+/team lead 写的工程文。如果说《Harness Engineering》定义了 agent 工程化的方法论,那这篇就是把方法论拉到生产级:怎么让一个 agent 持续工作几小时、几天、甚至几周,跨越多个 context window 和 sandbox,失败能恢复,留下结构化产物,断了能从断点接着干。
这个问题被 2026 年的三个大厂用类似的工程模式解掉:Anthropic 的 brain/hands/session 三分,Cursor 的 planner/worker/judge,Google 的 Agent Platform。Addy 把三家的实现并排放,提炼出收敛的工程模式:把 model loop / 执行 sandbox / 持久 session log 解耦,把生成 / 评估拆成两个 agent,把 compaction、hooks、context resets 烤进 harness,把 memory 暴露成 managed service。
读这篇前最好先读《Harness Engineering 全文》。Long-running 是 harness 的极限测试:harness 在 5 分钟任务上跑得稳不算什么,在 24 小时任务上不崩才是工程。
长跑 Agent(Long-running Agents)
原文:A long-running AI agent can keep making progress over hours, days, or weeks. It can do this across many context windows and sandboxes, recover from failure, leave structured artifacts behind, and resume where it left off.
长跑 AI agent 能在几小时、几天、甚至几周内持续做出推进。它能跨越多个 context window 和 sandbox 完成这件事,能从失败里恢复,留下结构化的工件,并从中断处接着干。
原文:For two years the dominant image of an “AI agent” has been a chat window with a clever loop in it. You type a goal, the agent calls some tools, you watch tokens stream by, you stop watching when the work runs out of patience or the context window fills up. That paradigm got us a long way, but it has a ceiling. The model forgets. It declares “task complete” when it isn’t. It re-introduces a bug it fixed nine turns ago. The whole thing is structured around a single sitting.
过去两年,“AI agent”主流的形象是:一个聊天窗口里跑着一个聪明的 loop。你输入一个目标,agent 调一些工具,你看着 token 一行行流出,要么是工作没耐心了你停下,要么是 context window 满了你停下。这个范式带我们走了很远,但有天花板。模型会忘记。它会在没做完时宣告”任务完成”。它会把九轮前修过的 bug 再次引入。整件事是围绕”一次坐下”这个时间单位组织的。
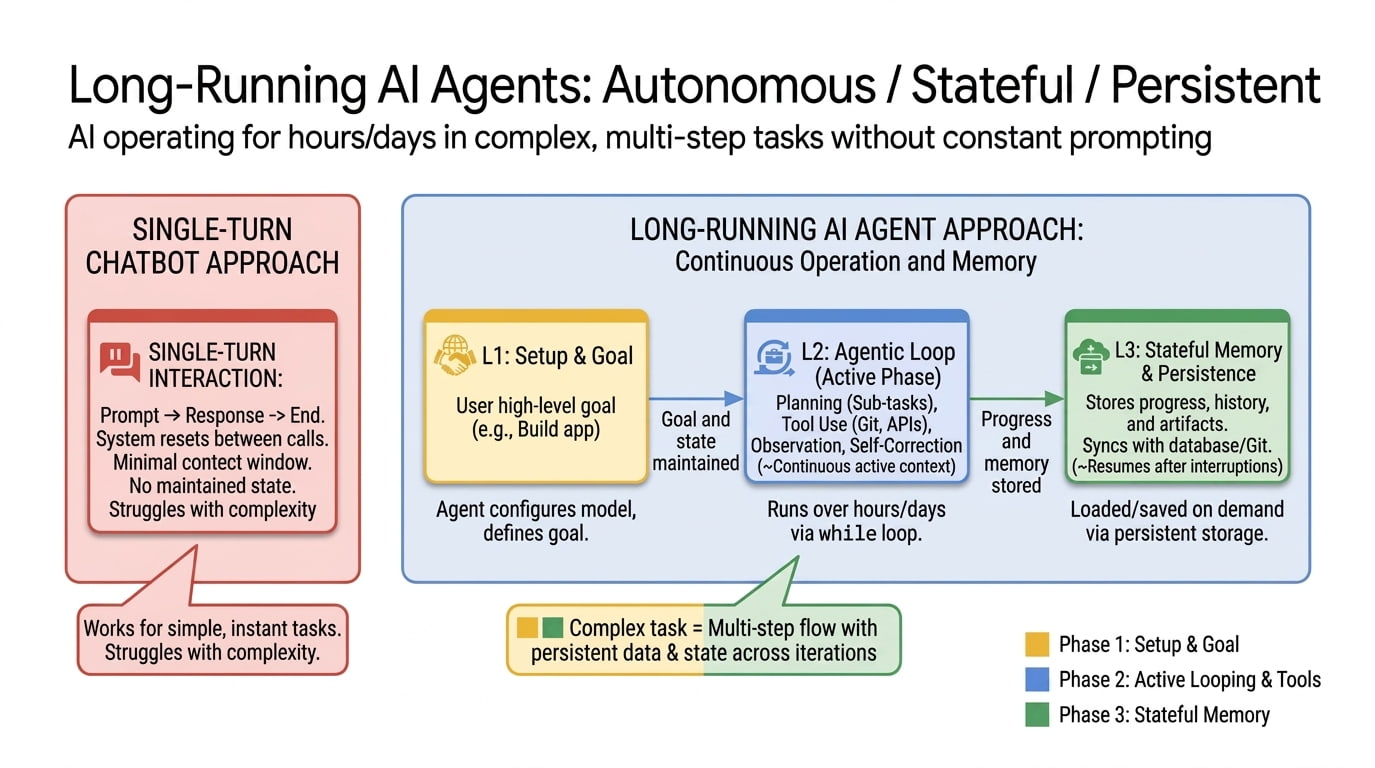
原文:Long-running agents are what comes next. The idea is easy to state: an agent that keeps making forward progress on a goal across many sessions and many sandboxes, possibly many days or weeks, while leaving the workspace clean enough that the next session can pick up where the last one left off. The engineering is harder. You have to solve for persistence, recovery, and verification in a way that doesn’t just paper over the cracks. You have to build a state layer that lives outside the model’s context window, and you have to design the handoff between sessions so the agent doesn’t lose its mind when it wakes up and finds itself in a different sandbox with a different context window.
长跑 agent 是下一步。思路好讲:一个 agent 跨越很多 session 和很多 sandbox,可能跨好几天或几周,持续向一个目标推进;同时保持工作区足够干净,让下一个 session 能从上一个的断点接着干。 工程难。你得用不糊弄的方式解决持久化(persistence)、恢复(recovery)、验证(verification);得搭一个住在模型 context window 之外的状态层;得设计 session 之间的交接,让 agent 在一个新的 sandbox、新的 context window 里醒来时不至于精神错乱。
原文:This post is my attempt to lay out what’s changed, who’s pushing on it, and how an engineer can use long-running agents today without writing the whole thing from scratch.
这篇文章是我的尝试:讲清楚发生了什么变化、谁在推进、以及一个工程师今天如何用上长跑 agent,而不必从零自己造一套。
“long-running”到底是什么意思
原文:“Long-running” gets used to mean at least three different things in practice, and it helps to keep them separate.
实际中”long-running”至少被用来指三种不同的东西,有必要拆开来谈。
原文:Long-horizon reasoning. The agent has to plan and execute over many dependent steps. This is mostly a model-quality story: coherence, planning, the ability to recover from a wrong turn ten steps ago. METR has been tracking this with their time horizon metric, which estimates how long a task a frontier model can complete with 50% reliability. The headline finding is that the metric has been doubling roughly every seven months since 2019, and their TH1.1 update earlier this year doubled the count of 8-hour-plus tasks in the eval set. If that curve holds, frontier agents complete tasks at the day scale by 2028 and the year scale by 2034.
Long-horizon reasoning(长跨度推理)。 agent 必须跨多个相互依赖的步骤做规划和执行。这主要是个模型质量问题:连贯性、规划、十步之前走错弯了能不能回头。METR 用他们的 time horizon 指标在跟踪这件事 —— 它估计一个前沿模型以 50% 可靠性能完成多长时间的任务。头条发现是:这个指标 从 2019 年开始大约每 7 个月翻一倍;他们今年早些时候的 TH1.1 更新 把 eval 集中”8 小时以上任务”的数量翻了倍。
原文金句:If that curve holds, frontier agents complete tasks at the day scale by 2028 and the year scale by 2034.
中译:如果这条曲线继续,前沿 agent 将在 2028 年完成”天”量级的任务,在 2034 年完成”年”量级的任务。
🟢 译者注:METR(Model Evaluation & Threat Research)是一家专做前沿模型能力评估的非营利,他们的 time horizon 指标在 AI 安全圈很被引用。Addy 在这里隐晦地引用 METR 的曲线给出一个长期预测 —— 这条曲线如果继续,2028 年的 agent 能独立做”一天活儿”,2034 年能做”一年活儿”。这是个非常激进的推断,但 Addy 的引用方式是中立的。
原文:Long-running execution. The agent’s process runs for hours or days. Maybe it’s a coding job, maybe it’s a research sweep, maybe it’s a 24/7 monitoring service. The model might be invoked thousands of times across the run. This is mostly a harness story, and it’s the one this post is mostly about.
Long-running execution(长跑执行)。 agent 的 进程 跑几个小时或几天。可能是编码任务,可能是研究扫荡,可能是 24/7 监控服务。模型可能在整个 run 里被调用上千次。这主要是 harness 的故事 —— 也是本文重点。
原文:Persistent agency. The agent has an identity that outlives any single task. It accumulates memory, learns user preferences, and is always available. This is the Memory Bank flavor of long-running.
Persistent agency(持久身份)。 agent 拥有一个超越任何单一任务的身份。它积累记忆、学习用户偏好、随叫随到。这是 Memory Bank 那种风味的 long-running。
原文:In practice the three blur together. A real production agent does long-horizon reasoning inside a long-running execution backed by persistent agency. But the engineering problems are different in each, and so are the products that solve them.
实际中三种会混在一起。一个真生产的 agent,在一个 long-running execution 里面 做 long-horizon reasoning,底下 由 persistent agency 支撑。但每一种的工程问题不一样,解决它们的产品也不一样。
为什么这件事重要
原文:There are two reasons I believe this work matters a lot right now.
我相信这件事现在重要,有两个原因。
原文:The first is a phase change in what’s economically feasible to delegate. An agent that runs for ten minutes can answer a question, summarize a doc, fix a small bug. An agent that runs for ten hours can own an entire feature, finish a migration that was on the backlog for six quarters, or do the kind of overnight research sweep that used to require a junior analyst. One of Anthropic’s Claude Sonnet announcements put concrete numbers on this last fall: 30+ hours of autonomous coding in internal tests, including one run that produced an 11,000-line Slack-style app. That’s already past the threshold where the answer to “should I delegate this?” is no longer obvious.
第一个,是**“经济上值得托付什么”出现了相变(phase change)**。一个跑十分钟的 agent 能回答问题、总结文档、修小 bug。一个跑十小时的 agent 能拥有一整个 feature、能做完积压了六个季度的迁移、能完成那种过去需要一个初级分析师彻夜的研究扫荡。 Anthropic 去年秋天的 Claude Sonnet 公告 给出了具体数字:内部测试中 30+ 小时的自主编码,其中 一次 run 产出了一个 11000 行的 Slack 类应用。
原文金句:That’s already past the threshold where the answer to “should I delegate this?” is no longer obvious.
中译:这已经越过了那条门槛 —— “我该不该把这件事丢给 agent”的答案不再显而易见。
原文:The second is that persistence changes what the agent is. A stateless agent answers your question and disappears. A long-running one accumulates context: which competitor moved which way last week, which test flaked twice on Tuesday, what you usually mean by “the dashboard.” Anthropic’s Project Vend was the most public early demonstration of this. They had a Claude instance run an actual office vending business for a month, managing inventory, setting prices, talking to suppliers. It failed in informative ways, and the second phase ran much better, but the point wasn’t profitability. The point was watching what kinds of weird coherence problems show up when an agent has to maintain identity across weeks instead of turns.
第二个,是持久化改变了 agent 是什么。一个无状态 agent 回答完你的问题就消失。一个长跑 agent 积累上下文:哪个竞品上周怎么动了、周二哪个测试 flake 过两次、你说”那个 dashboard”通常指的是哪个。Anthropic 的 Project Vend 是这件事最早的公开演示 —— 他们让一个 Claude 实例真的运营一个办公室自动售货机生意一个月:管库存、定价、和供应商沟通。它以信息量很大的方式失败了;第二期 跑得好多了,但重点不在盈利,而在观察:当 agent 必须跨周(而不是跨轮次)维持身份时,会冒出什么诡异的连贯性问题。
原文:Those are the same problems every team building production agents now hits.
这些就是现在每一个做生产级 agent 的团队会撞上的问题。
🟢 译者注:Project Vend 是 Anthropic 2025 年做的一个非常出圈的实验:让 Claude 真的运营一个无人售货摊位,赚钱、管理库存、应付奇怪客户。第一阶段它制造了不少笑话(被人骗、价格设错、莫名其妙存货堆积),但 Anthropic 公开发布报告本身就是一种科普,让公众第一次看到”agent 长跑会出什么问题”这件事。
每个长跑 agent 都会撞上的三堵墙
原文:Three walls show up in basically every write-up I’ve read this year.
今年我读到的几乎每篇相关文章,都在描述同样三堵墙。
原文:Finite context. Even a 1M-token window fills. And context rot, the steady degradation of model performance as the window gets full, kicks in well before the hard limit. A 24-hour run is not going to fit in any context window the field has on its roadmap. Something has to give.
有限的 context。 就算 1M token 的窗口也会满。而 context rot —— 上下文越满模型表现越差的稳定退化 —— 在硬上限之前就开始作祟。一个 24 小时的 run 不会装进领域路线图上的任何一个 context window。 必须舍掉点什么。
原文:No persistent state. A new session starts blank. Anthropic’s framing in their scientific computing post is the cleanest version I’ve seen: “imagine a software project staffed by engineers working in shifts, where each new engineer arrives with no memory of what happened on the previous shift.” Without an explicit persistence story, every shift change is a productivity disaster.
没有持久状态。 新 session 是白板。Anthropic 在 科学计算那篇 里的 framing 是我见过最干净的:
原文金句:imagine a software project staffed by engineers working in shifts, where each new engineer arrives with no memory of what happened on the previous shift.
中译:想象一个软件项目,工程师们轮班工作,每个新到岗的工程师都对前一班发生的一切毫无记忆。
如果没有明确的持久化故事,每次换班都是一次生产力灾难。
原文:No self-verification. Models reliably skew positive when they grade their own work. Asked “are you done?” they answer “yes” more often than they should. Without a separate signal that the work meets a bar, you get the agent that ships at 30% complete with full confidence.
无法自验证。 模型给自己打分时,几乎一定会偏向正面。问”你做完了吗?“,它说”是”的频率比应该说的更高。如果没有一个独立信号告诉你工作达到了 bar,你就会得到一个完成度 30%、却信心爆棚地宣告交付的 agent。
原文:Long-running agent designs are mostly answers to these three problems. The major labs have converged on similar shapes of answer, but with very different surface area.
长跑 agent 的设计,大体是这三个问题的答案。
原文金句:The major labs have converged on similar shapes of answer, but with very different surface area.
中译:大厂在答案的形状上趋同,但暴露给开发者的接触面非常不同。
Ralph loop:实践者最简单的长跑 agent 之一
原文:The Ralph loop (sometimes called the Ralph Wiggum technique) is one of “simpler” practitioner version of long-running agents, popularized by Geoffrey Huntley and Ryan Carson. The reference implementation is literally a bash script that loops:
Ralph loop(有时叫 Ralph Wiggum 技术)是实践者版本里最”简单”的长跑 agent 之一,由 Geoffrey Huntley 和 Ryan Carson 推广开。它的参考实现 字面上就是一个 bash 脚本 在 loop:
原文:
- Pick the next unfinished task from a list (
prd.jsonor equivalent).- Build a prompt with the task, the relevant context, and any persistent notes.
- Call the agent.
- Run tests or other checks.
- Append what happened to
progress.txt.- Update the task list (done, failed, blocked).
- Go back to step 1.
- 从一个清单(
prd.json或等价物)里挑下一个未完成的 task。 - 用这个 task、相关 context、所有持久化笔记拼一个 prompt。
- 调 agent。
- 跑测试或其他检查。
- 把发生的事追加到
progress.txt。 - 更新 task list(done / failed / blocked)。
- 回到第 1 步。
原文:The reason it works is the same reason any of the harnesses below work: state lives outside the agent’s context.
prd.jsonis the plan,progress.txtis the lab notes,AGENTS.mdis the rolling rulebook. The agent itself is amnesiac, but the filesystem isn’t. Each iteration starts fresh and reads enough state from disk to keep going. Carson’s Compound Product extends the idea by chaining multiple loops (an analysis loop that reads daily reports, a planning loop that emits a PRD, an execution loop that writes the code), which is roughly the open-source version of the planner-generator-evaluator triad Anthropic landed on independently.
它能 work,和下面每一个 harness 能 work 是同样的原因:状态住在 agent 的 context 之外。prd.json 是计划,progress.txt 是实验记录,AGENTS.md 是滚动更新的规则手册。
原文金句:The agent itself is amnesiac, but the filesystem isn’t.
中译:agent 本身有失忆症,但 filesystem 没有。
每次 iteration 干净启动,从磁盘读够状态接着干。Carson 的 Compound Product 把这个思路扩展成链:一个分析 loop 读每日报告,一个规划 loop 产出 PRD,一个执行 loop 写代码 —— 这大致是 Anthropic 独立得出的 planner-generator-evaluator 三件套的开源版本。
原文:I went deeper on all of this in Self-improving agents: task list structure, progress files, QA gates, monitoring, the failure modes you’ll actually hit. The short version is that you can build a working long-running agent in an evening with a bash script and a JSON file. Most of what Google and Anthropic have productized is the work of making this pattern recoverable, secure, and observable at scale.
我在 Self-improving agents 里更深入讲了这一切:task list 结构、progress 文件、QA gates、监控、你真会撞上的失败模式。短版本是:你可以用一个 bash 脚本 + 一个 JSON 文件,在一个晚上搭出一个能 work 的长跑 agent。 Google 和 Anthropic 产品化的工作,大部分是把这个模式做得在规模化下可恢复、安全、可观测。
原文:The big-lab stories below are different ways of paying for that production-readiness.
下面大厂的故事,是为这种生产就绪性付出代价的不同方式。
🟢 译者注:Ralph loop 的精髓是”agent 失忆,文件系统不失忆” —— 这是一种非常便宜、但非常聪明的状态分离。如果你今天想自己动手玩玩,Geoffrey Huntley 的 ghuntley.com/ralph 那个 bash 脚本是 100 行内的全部参考实现。
Anthropic:harness,然后 brain / hands / session 三分
原文:Anthropic has been the most public about the engineering. Two posts are worth reading end-to-end.
Anthropic 在工程细节上最公开。两篇博客值得从头读到尾。
原文:The first is “Effective harnesses for long-running agents”, which lays out a two-agent harness for autonomous full-stack development. An initializer agent runs once at the start of a project to set up the environment, expand the prompt into a structured
feature-list.json, and write aninit.shthat future sessions will run on boot. A coding agent is then woken up over and over, each session asked to make incremental progress on one feature, run tests, leave aclaude-progress.txtnote, and commit. A test ratchet (“it is unacceptable to remove or edit tests because this could lead to missing or buggy functionality”) sits in the prompt to stop the very common failure of an agent deleting failing tests to “make them pass.” InfoQ’s writeup extends this into a planner, generator, and evaluator triad, on the same logic that separating generation from evaluation matters because models grade their own work too generously.
第一篇是 《Effective harnesses for long-running agents》,它给出了一个用于自主全栈开发的双 agent harness。
- initializer agent(初始化 agent)在项目开始时跑一次,搭好环境,把 prompt 扩展成一个结构化的
feature-list.json,写出一个init.sh—— 后续所有 session 启动时都会跑它。 - coding agent 然后被反复唤醒,每个 session 被要求在一个 feature 上做增量推进、跑测试、留一份
claude-progress.txt笔记、commit。
一条测试棘轮规则——“删除或编辑测试是不可接受的,因为这可能导致功能缺失或带 bug” —— 直接坐在 prompt 里,阻止那个非常常见的失败:agent 为了”让测试通过”而把失败的测试删掉。InfoQ 的报道 把这个扩展到 planner / generator / evaluator 三件套,同样的逻辑:把生成和评估分开很重要,因为模型给自己工作打分时太宽容。
原文:The second is “Scaling Managed Agents: Decoupling the brain from the hands”, the architectural post behind Claude Managed Agents (Anthropic’s hosted runtime, launched in early April). The argument is that an agent has three components that should be independently replaceable. The Brain is the model and the harness loop that calls it. The Hands are sandboxed, ephemeral execution environments where tools actually run. The Session is an append-only event log of every thought, tool call, and observation.
第二篇是 《Scaling Managed Agents: Decoupling the brain from the hands》,也就是 Claude Managed Agents(Anthropic 4 月初上线的托管 runtime)背后的架构文章。它的论点是:一个 agent 由三个应该独立可替换的组件组成:
- Brain(大脑):模型 + 调用它的 harness loop。
- Hands(双手):沙盒化、易失的执行环境 —— 工具真正在这里运行。
- Session(会话):每一次思考、tool call、observation 的 append-only 事件日志。
原文:This sounds abstract and it isn’t. Anthropic’s framing: “every component in a harness encodes an assumption about what the model can’t do on its own.” When you couple them, an assumption that goes stale (e.g., the model used to need an explicit planner and now plans natively) means the whole system has to change at once. When you decouple them, the harness becomes stateless, sandboxes become cattle, not pets, and a brain crash doesn’t lose the run. A fresh container calls
wake(sessionId)and reconstitutes the state from the log. They reported time-to-first-token dropped ~60% at p50 and over 90% at p95 just from being able to start inference before the sandbox is ready.
听起来很抽象,其实不是。Anthropic 的 framing:“harness 里每个组件都编码了一个’模型自己做不到什么’的假设。” 当你把它们耦合在一起,任何一个假设过时了(比如模型以前需要显式 planner、现在自带规划)就意味着整个系统要一次性改完。把它们解耦,harness 变成 stateless,sandbox 变成 cattle, not pets,brain 崩了也不会丢失整个 run。一个新容器调一下 wake(sessionId),从 log 里重建状态。他们报告说,仅仅因为能在 sandbox 准备好之前就启动 inference,p50 的 time-to-first-token 下降了约 60%,p95 下降了 90% 以上。
🟢 译者注:“cattle, not pets” 是 SRE 圈的经典口号(出自 Microsoft 的 Bill Baker)。Pets 是你给宠物起名字、生病了带去看医生;Cattle 是你给牛打编号、生病了直接淘汰换新的。这里的意思是:sandbox 不要被精心维护,坏了就杀掉重起,状态在 session log 里。
原文:The session-as-event-log idea is the part most teams underappreciate. It is what makes a long-running agent recoverable. Without it, a container failure is a session failure and you’re debugging into a stale snapshot. With it, the agent’s memory is a queryable artifact that lives outside whatever process happens to be running at the moment.
原文金句:The session-as-event-log idea is the part most teams underappreciate.
中译:“把 session 当成事件日志”这个想法,是大多数团队没充分理解的部分。
它就是让长跑 agent 可恢复的那块。没有它,容器故障就是 session 故障,你只能对着一个过时的快照 debug。有了它,agent 的记忆变成一个可查询的工件,住在任何当下进程的外面。
原文:For the scientific computing crowd, Anthropic’s long-running Claude post reduces all of this to a simpler stack:
CLAUDE.mdas a living plan the agent edits as it learns,CHANGELOG.mdas portable lab notes,tmuxplusSLURMplusgitas the execution and coordination layer, and the Ralph loop, aforloop that kicks the agent back into context whenever it claims completion and asks if it’s really done. Their flagship case study is a Boltzmann solver Claude Opus 4.6 built over a few days that reached sub-percent agreement with a reference CLASS implementation. Months-to-years of researcher time, compressed.
对做科学计算的人,Anthropic 的 long-running Claude 那篇 把这一切简化成一个更简单的栈:CLAUDE.md 作为 agent 在学习中持续编辑的活计划,CHANGELOG.md 作为可移植的实验记录,tmux + SLURM + git 作为执行和协调层,然后是 Ralph loop —— 一个 for 循环,只要 agent 自称完成就把它踢回 context 问”真的吗”。他们的旗舰案例是:一个 Boltzmann solver,Claude Opus 4.6 几天内构建,与参考实现 CLASS 达到了亚百分点的一致性。几个月到几年的研究员时间,被压缩了。
🟢 译者注:Boltzmann solver / CLASS 是宇宙学计算的基础设施(求解原初宇宙的 Boltzmann 方程,模拟微波背景辐射等)。CLASS 是该领域 reference 工具,通常需要博士级专家维护几年。Claude 几天内做出亚百分点匹配 = 业内大新闻。
原文:Same patterns across all three posts: an explicit plan file, an explicit progress file, structured handoffs between sessions, separate generation from evaluation, and a loop that refuses to let the agent stop early.
三篇文章里共同的模式:一个明确的 plan file、一个明确的 progress file、session 之间的结构化交接、把生成与评估分开、一个拒绝让 agent 提前停止的 loop。
Cursor:planners、workers、judges
原文:Cursor’s “Scaling long-running autonomous coding” is the other essential read this year. They walked into walls that Anthropic mostly papered over.
Cursor 的《Scaling long-running autonomous coding》 是今年另一篇必读。他们撞上了 Anthropic 大体上避开了的几堵墙。
原文:Their first attempt was a flat coordination model: equal-status agents writing to shared files with locks. It became a bottleneck and made the agents risk-averse, churning rather than committing. Their second attempt swapped locks for optimistic concurrency control, which removed the bottleneck but didn’t fix the coordination problem. The third design is what’s running in production now and what they describe as solving most of the problem:
第一次尝试是扁平的协调模型:地位平等的 agent 用锁写共享文件。它变成瓶颈,而且让 agent 变得规避风险 —— 打转(churning)而不提交。第二次尝试把锁换成乐观并发控制(optimistic concurrency control),消除了瓶颈但没解决协调问题。第三次设计是现在跑在生产环境里的那个,他们说它解决了大部分问题:
原文:
- Planners continuously explore the codebase and emit tasks. They can recursively spawn sub-planners.
- Workers are focused executors. They don’t coordinate with each other and they don’t worry about the big picture.
- Judges decide when an iteration is finished and when to restart.
- Planners 持续探索代码库并发出 task。他们可以递归派生 sub-planner。
- Workers 是聚焦的执行者。他们彼此不协调,也不担心全局图景。
- Judges 决定一次 iteration 何时完成、何时重启。
原文:Two things stand out from the post. One: “a surprising amount of the system’s behavior comes down to how we prompt the agents” more than the harness or the model. Two: different models slot into different roles. Their reported finding is that a GPT model was better than Opus for extended autonomous work specifically because Opus tended to stop early and take shortcuts. Same task, different role, different model. The matching is becoming part of the design surface.
文章里有两点突出。
第一:“令人惊讶的是,系统行为有相当大的比例归结为我们怎么 prompt agent”,胜过 harness 或模型本身。
第二:不同模型适合不同角色。他们报告说,在 延伸的自主工作 上,一个 GPT 模型表现比 Opus 更好,具体原因是 Opus 倾向于早停 + 走捷径。
原文金句:Same task, different role, different model.
中译:同一个任务,不同角色,不同模型。
匹配本身正在成为设计面的一部分。
原文:This pairs with Composer 2 (their proprietary frontier coding model that ships in Cursor 3) and their background cloud agents: long-running tasks that run on Anysphere’s cloud infrastructure rather than your laptop. Eight-hour refactors and codebase-wide migrations survive a closed lid. You can start a task locally, hit run in cloud when you realize it’ll take 30 minutes, and re-attach later from your phone. Each agent runs in an isolated git worktree and merges back via PR. The handoff between local and remote is the part most teams haven’t figured out yet, and Cursor’s bet is that it has to be its own product surface.
这与 Composer 2(他们专有的前沿编码模型,随 Cursor 3 出货)和他们的 background cloud agents 配合:长跑任务跑在 Anysphere 的云基础设施上,而不是你笔记本上。8 小时重构、跨代码库迁移,合上盖子也能存活。 你可以本地启动一个任务,意识到要 30 分钟时按 run in cloud,稍后从手机重新接入。每个 agent 跑在隔离的 git worktree 里,通过 PR 合回来。本地和远程之间的交接,是大多数团队还没搞清楚的部分,Cursor 的赌注是它必须成为一个独立的产品面。
原文:The shape ends up close to Anthropic’s: roles are split, sessions are durable, judges sit beside the worker, and a long task runs in a cloud sandbox with git as the coordination substrate.
最终形状和 Anthropic 接近:角色拆分,session 持久,judge 坐在 worker 旁边,长任务跑在云 sandbox 里,git 作为协调底层。
Google:Agent Platform 上的长跑 agent
原文:Google’s announcement at Cloud Next ‘26 two weeks ago folded Vertex AI into the Gemini Enterprise Agent Platform and turned long-running agents into a named product, with named SLAs.
Google 两周前在 Cloud Next ‘26 的公告,把 Vertex AI 折叠进 Gemini Enterprise Agent Platform,并把长跑 agent 变成了一个有名字的产品,带具名 SLA。
原文:The pieces that matter for this post:
对本文重要的几块:
原文:- Agent Runtime supports agents that “run autonomously for days at a time” with sub-second cold starts and on-demand sandbox provisioning. The launch post’s example use case is a sales prospecting sequence that takes a week to play out, which is roughly the right shape for it.
- Agent Runtime 支持 “一次自主运行数天” 的 agent,亚秒级冷启动,按需 sandbox 提供。发布文章的示例用例是一个跨一周展开的销售开发序列,这个形状大致合适。
原文:- Agent Sessions persist conversation and event history. You can pin them to a custom session ID that maps to your own CRM or DB record, so the agent’s state lives next to the business state instead of in a separate AI silo.
- Agent Sessions 持久化对话和事件历史。你可以把它们 pin 到一个自定义 session ID,映射到你自己的 CRM 或 DB 记录上,让 agent 状态住在业务状态旁边,而不是另起一个 AI silo。
原文:- Agent Memory Bank is the persistent long-term memory layer, generally available as of Next ‘26. It curates memories from sessions, scopes them to a user identity, and exposes a search API so the next agent invocation can pull what’s relevant. Payhawk reported that auto-submitting expenses through a Memory-Bank-backed agent cut submission time by over 50%.
- Agent Memory Bank 是持久长期记忆层,Next ‘26 起 GA。它从 session 中策展记忆,按用户身份做 scope,暴露一个 search API,让下一次 agent 调用能拉出相关信息。Payhawk 报告说,通过 Memory-Bank 支持的 agent 自动提交报销,提交时间减少超过 50%。
原文:- Agent Sandbox handles hardened code execution.
- Agent Sandbox 处理加固的代码执行。
原文:- Agent-to-Agent Orchestration, Agent Registry, Agent Identity, Agent Gateway, Agent Observability, and Agent Simulation cover basically every operational concern you’d otherwise build by hand for a production fleet, including the cryptographic-identity-and-audit-log story enterprises actually need to ship.
- Agent-to-Agent Orchestration、Agent Registry、Agent Identity、Agent Gateway、Agent Observability、Agent Simulation 基本覆盖了你为生产 fleet 所有原本要手工搭的运维关切 —— 包括企业真正需要才能出货的”加密身份 + 审计日志”那一套。
原文:Architecturally this is the same brain/hands/session split Anthropic described, just productized at platform scale and bundled with ADK (the code-first dev kit) and Agent Studio (the visual one). If you’re building inside Google Cloud, you don’t have to design a session log or a memory store from scratch anymore. You wire an ADK agent into Memory Bank and Sessions, deploy onto Agent Runtime, and the persistence question is answered.
架构上这就是 Anthropic 描述的那个 brain/hands/session 三分,只是被产品化到平台规模,并和 ADK(代码优先的开发包)、Agent Studio(视觉版)捆绑发布。如果你在 Google Cloud 里构建,你不必再从零设计 session log 或 memory store。把一个 ADK agent 接到 Memory Bank 和 Sessions,部署到 Agent Runtime —— 持久化问题就回答完了。
原文:Notice how much this looks like the pattern Anthropic and Cursor describe, just unbundled into named services with SLAs. Three years ago you’d have built all of this yourself. Now you pick which version of “decoupled brain, hands, and session” you want to rent.
注意这有多像 Anthropic 和 Cursor 描述的模式,只是被解绑成了带 SLA 的具名服务。三年前你得全部自己搭。
原文金句:Now you pick which version of “decoupled brain, hands, and session” you want to rent.
中译:现在你选你想租哪个版本的”brain、hands、session 解耦”。
5 个生产级长跑 agent 模式
原文:Shubham Saboo and I wrote up five design patterns we’ve seen separate working long-running agents from demos. They aren’t Google-specific, but they map cleanly onto the primitives Agent Runtime now exposes, so it’s worth walking through them here in shortened form.
Shubham Saboo 和我 写过 5 个设计模式,这些模式把”能 work 的长跑 agent”和”demo”区分开。它们不是 Google 专属,但能干净地映射到 Agent Runtime 现在暴露的原语上,所以这里值得用缩短版走一遍。
原文:Checkpoint-and-resume. The most common multi-day failure is context loss. An agent processes 200 documents over four hours, hits an error on document 201, and without a checkpoint you start from scratch. Treat the agent like a long-running server process: write intermediate state to disk, checkpoint every N units of work, recover from failures. The Agent Runtime sandbox gives you a persistent filesystem, but choosing the right checkpoint granularity (not every step, not only the end) is on you.
1. Checkpoint-and-resume(检查点与恢复)。 跨天最常见的失败是 context 丢失。agent 4 小时处理 200 份文档,在第 201 份上撞错,没有 checkpoint 就从头来。把 agent 当一个长跑 server 进程对待:把中间状态写到磁盘,每 N 个工作单元做 checkpoint,从失败中恢复。Agent Runtime 的 sandbox 给你持久 filesystem,但选对 checkpoint 粒度(不是每一步,也不是只在最后)是你的事。
原文:Delegated approval (human-in-the-loop). Most “human-in-the-loop” implementations are: serialize state to JSON, fire a webhook, hope someone responds. The state goes stale, the notification gets buried, the agent re-deserializes into a slightly different world. Long-running runtimes let the agent pause in place with full execution state intact: reasoning chain, working memory, tool history, pending action. Hours of human time pass, the agent consumes zero compute, and it resumes with sub-second latency. Mission Control is Google’s inbox for this. The pattern works regardless of vendor.
2. Delegated approval(委派审批,human-in-the-loop)。 大多数 “human-in-the-loop” 实现是:把状态序列化成 JSON、触发一个 webhook、祈祷有人回应。状态过期,通知被淹没,agent 反序列化进一个略微不同的世界。长跑 runtime 让 agent 原地暂停,完整执行状态保持不变:推理链、工作记忆、工具历史、待办动作。人类时间过去几小时,agent 消耗零算力,亚秒级延迟恢复。Google 的 Mission Control 是给这件事的收件箱。模式不挑供应商。
原文:Memory-layered context. A seven-day agent needs more than session state. Memory Bank handles long-term curated memory, Memory Profiles add low-latency lookups, and the failure mode you’ll hit in production is memory drift: the agent learns a procedural shortcut from a few atypical interactions and starts applying it broadly. Govern memory like you govern microservices. Agent Identity controls who can read and write which banks. Agent Registry tracks which version of which agent is running. Agent Gateway enforces policy on the wire. The auditing question stops being “what are my agents doing?” and becomes “what are my agents remembering, and how is that changing their behavior?”
3. Memory-layered context(分层记忆 context)。 七天的 agent 需要的比 session state 多。Memory Bank 处理长期策展记忆,Memory Profiles 加低延迟查找,生产中你会撞上的失败模式是 memory drift:agent 从几次非典型交互里学到一个流程捷径,然后开始广泛应用它。
原文金句:Govern memory like you govern microservices.
中译:像治理 microservice 一样治理 memory。
Agent Identity 控制谁能读写哪些 bank。Agent Registry 追踪哪个版本的哪个 agent 在跑。Agent Gateway 在通信线上强制 policy。审计问题从”我的 agent 在做什么”变成”我的 agent 在记什么,这怎么改变了它们的行为”。
原文:Ambient processing. Not every long-running agent talks to a human. Some sit on a Pub/Sub stream or a BigQuery table and act on events as they arrive: content moderation, anomaly detection, inbox triage. The architectural decision worth making early is to not hardcode policy into the agent. Define it in the Gateway and the fleet picks up policy changes without redeploys. Ambient agents run unsupervised for long stretches, and the only sane way to update a hundred of them is to update the policy layer once.
4. Ambient processing(环境处理)。 不是每个长跑 agent 都和人对话。有些坐在一条 Pub/Sub stream 上或一张 BigQuery 表上,事件到来时就行动:内容审核、异常检测、收件箱分流。值得早做的架构决定是:不要把 policy 硬编码进 agent。把它定义在 Gateway 上,fleet 不需要重新部署就能感知 policy 变化。Ambient agent 长时间无人监督地运行,更新一百个 agent 的唯一理智方式是一次性更新 policy 层。
原文:Fleet orchestration. In real systems, you rarely have one agent. A coordinator delegates sub-tasks to specialists (a Lead Researcher Agent, a Scoring Agent, an Outreach Agent), each running independently for different durations. Each specialist gets its own Identity (so the Outreach Agent can’t read financial data meant for Scoring), its own policy enforcement, its own Registry entry. This is the same coordinator/worker shape distributed systems have used for decades. What’s new is that ADK handles it declaratively with graph-based workflows, and a bad deployment in one specialist doesn’t cascade to the others.
5. Fleet orchestration(舰队编排)。 真系统里很少只有一个 agent。一个 coordinator 把子任务委派给专家(Lead Researcher Agent、Scoring Agent、Outreach Agent),各自独立运行不同时长。每个专家都有自己的 Identity(所以 Outreach Agent 读不到给 Scoring 的财务数据)、自己的 policy enforcement、自己的 Registry entry。这就是分布式系统几十年用的 coordinator/worker 形状。新东西是:ADK 用基于图的 workflow 声明式地处理它,某个专家的坏部署不会级联到其他。
原文:The patterns compose. A compliance system might use checkpointing for document processing, delegated approval for review gates, memory layering for cross-session knowledge, and fleet orchestration to coordinate the specialists. The opening question is always the same: what’s the longest uninterrupted unit of work your agent needs to perform? Minutes, and you don’t need long-running agents. Hours or days, and these patterns are where to start. The full write-up with code samples covers each pattern in depth.
这些模式可以组合。一个合规系统可能用 checkpointing 处理文档、用 delegated approval 做审查 gate、用 memory layering 做跨 session 知识、用 fleet orchestration 协调专家。开篇问题始终一样:你的 agent 需要执行的最长不被打断工作单元是多长? 分钟级,你不需要长跑 agent。小时或天级,这些模式是起点。 带代码示例的完整版本 深入讲了每个模式。
那今天到底怎么搭一个?
原文:This is the practical question and it has a different answer depending on what you’re building.
这是实践问题,根据你在搭什么,答案不同。
原文:You’re a developer who wants long-running coding work on your own repo. Just use Claude Code (or Antigravity, Cursor, or Codex). The harness is already there. Treat your
AGENTS.mdlike a pilot’s checklist: short, every line earned by a real failure. Add hooks for typecheck and lint that surface failures back to the agent. Write a plan file before the agent starts. Use the Ralph loop when the agent claims it’s done and you don’t believe it. For multi-hour or overnight jobs, run in a worktree so a closed laptop doesn’t kill the run, and have it commit progress every meaningful unit of work. This is the path most people should take, and it’s where the most leverage is right now.
你是开发者,想在自己的 repo 上做长跑编码。 直接用 Claude Code(或 Antigravity、Cursor、Codex)。harness 已经在那。把你的 AGENTS.md 当飞行员 checklist:简短,每一行都被真实失败挣来。加 typecheck / lint 的 hooks,把失败反馈回 agent。在 agent 开始前写一个 plan file。当 agent 自称做完而你不信时,用 Ralph loop。对几小时或彻夜的任务,在 worktree 里跑,这样合上笔记本不会杀掉 run,并让它每个有意义的工作单元就 commit 一次进度。
原文金句:This is the path most people should take, and it’s where the most leverage is right now.
中译:这是大多数人该走的路,也是当下杠杆最大的地方。
原文:You’re building a hosted agent product. Don’t build the runtime. Pick a managed one. The three real options today: Google’s Agent Platform (Agent Engine + Memory Bank + Sessions), Claude Managed Agents, or roll something on top of ADK, the Claude Agent SDK, or Codex SDK and host it yourself. The trade-off is the usual one. Managed gets you the brain/hands/session split, observability, identity, and an audit trail out of the box. Self-hosted gets you control and the ability to use weird models for weird roles (Cursor’s pattern). For most teams, the right starting point is a managed runtime plus your own ADK or SDK code for the actual loop.
你在搭一个托管 agent 产品。 不要自己搭 runtime。挑一个 managed 的。今天三个真选项:Google 的 Agent Platform(Agent Engine + Memory Bank + Sessions);Claude Managed Agents;或者基于 ADK / Claude Agent SDK / Codex SDK 自己搭 + 自己 host。取舍是老一套:Managed 让你开箱获得 brain/hands/session 拆分、可观测、identity、审计;自托管给你控制权,以及”在奇怪角色上用奇怪模型”的能力(Cursor 的模式)。对大多数团队,正确起点是 managed runtime + 你自己用 ADK 或 SDK 写 loop 逻辑。
原文:You’re doing something autonomous and operational (monitoring, research, ops). Memory Bank-style persistence is what you want, and it’s the part that doesn’t exist in Claude Code. ADK + Memory Bank + Cloud Run + Cloud Scheduler is the cleanest stack I’ve seen for “agent runs every N hours, accumulates state, alerts on a threshold.” This is also where Cursor’s planner/worker/judge split starts to matter more than it does for IDE coding, because the work is genuinely parallel and the failure modes are different.
你在做自主性 + 运营性的东西(监控、研究、运维)。你想要的是 Memory Bank 风味的持久化,这部分 Claude Code 没有。ADK + Memory Bank + Cloud Run + Cloud Scheduler 是我见过最干净的栈,对应”每 N 小时跑一次的 agent,积累状态,达到阈值时告警”。这也是 Cursor 的 planner/worker/judge 拆分,比在 IDE 编码场景更重要的地方 —— 因为这种工作真正并行,失败模式也不同。
原文:A few things matter regardless of which path you take.
不管走哪条路,有几件事都重要。
原文:Write down the done-condition before the agent starts. This is the single highest-leverage move for long runs. The Anthropic harness post calls it the feature list; Cursor calls it the planner’s task spec. Either way, it’s an external file with explicit, testable completion criteria, and it exists so the agent can’t quietly redefine done mid-run.
在 agent 开始之前把”做完的条件”写下来。 这是长跑场景里杠杆最大的单一动作。Anthropic harness 文章叫它 feature list,Cursor 叫它 planner 的 task spec。无论怎么叫,它是一个外部文件,明确、可测试的完成标准,它存在的意义是不让 agent 在 run 到一半时悄悄重新定义”完成”。
原文:Separate the evaluator from the generator. Self-grading is the failure mode. A planner / worker / judge pipeline, or a generator / evaluator pair, is a real architectural pattern not a stylistic preference. Even if it’s the same model in different roles with different prompts.
把 evaluator 和 generator 分开。 自评是失败模式。planner / worker / judge 管道、或 generator / evaluator 双件套,是真实的架构模式,不是风格偏好。即使是同一个模型,在不同角色、用不同 prompt,也算。
原文:Invest in the session log, not just the prompt. The append-only event log is what makes the agent recoverable, debuggable, and auditable. If you can’t reconstruct what the agent did in the last 24 hours from durable storage, what you have is a long-running shell script that happens to call an LLM, not a long-running agent.
在 session log 上投入,不只在 prompt 上。 append-only 事件日志,才是让 agent 可恢复、可 debug、可审计的关键。
原文金句:If you can’t reconstruct what the agent did in the last 24 hours from durable storage, what you have is a long-running shell script that happens to call an LLM, not a long-running agent.
中译:如果你不能从持久存储里重建 agent 在过去 24 小时做了什么,你拥有的就是一个恰好调了 LLM 的长跑 shell 脚本,不是一个长跑 agent。
原文:Treat compaction and context resets as first-class. Anthropic is explicit that summarization-as-compaction wasn’t enough for very long jobs; they had to do full context resets where the harness tears the session down and rebuilds it from a structured handoff file. It is essentially how humans onboard a new engineer.
把 compaction 和 context reset 视为一等公民。 Anthropic 明确说,对很长的任务,“摘要式 compaction”不够;他们必须做完整的 context reset,harness 拆掉整个 session,从一份结构化交接文件重建。这本质上就是人类入职新工程师的方式。
一些真实的局限
原文:A few things are still genuinely unsolved.
有几件事仍然真没解决。
原文:Cost. A 24-hour run with a frontier model and a few tools is not cheap. Without budgets, circuit breakers, and a hard cap on tool spend, an agent can quietly burn through a week’s API budget in an afternoon. This is solvable, but it’s an explicit step you have to take.
成本。 用前沿模型 + 几个工具跑 24 小时不便宜。没有预算、熔断器、工具开销硬上限,一个 agent 可以在一个下午静悄悄烧光你一周的 API 预算。可解,但你必须显式做这一步。
原文:Security. A long-running agent with API keys, cloud access, and the ability to run shell commands has a much larger attack surface than a chat session. The brain/hands separation pattern matters here too: credentials should be unreachable from the sandbox where model-generated code runs, which is one of the benefits Anthropic calls out for Managed Agents.
安全。 一个有 API keys、云访问、shell 执行能力的长跑 agent,攻击面比聊天 session 大得多。brain/hands 分离模式在这里也重要:凭证应该从模型生成代码所跑的 sandbox 里够不到 —— 这是 Anthropic 在 Managed Agents 里强调的好处之一。
原文:Alignment drift. Over many context windows, agents drift. The original goal gets summarized, then re-summarized, then loses fidelity. This is the part hooks and judges exist to defend against. It is also the most common reason “the agent went off and did something I didn’t ask for.”
对齐漂移(alignment drift)。 跨过很多 context window,agent 会漂。原始目标被摘要、再摘要,失真。 这就是 hooks 和 judges 存在的防御对象。也是”agent 跑偏去做了我没让它做的事”最常见的原因。
原文:Verification. Auditing 24 hours of autonomous activity is a real human-time problem. Observability and structured artifacts (PRs, commits, briefings, test runs) are how you make this tractable. Without them, you’re scrolling logs and you’ll miss what matters.
验证。 审计 24 小时的自主活动,是一个真实的”人类时间”问题。可观测性 + 结构化产物(PR、commit、briefing、test run)是让这件事可处理的方式。 没有它们,你只能滚动日志,而你会漏掉真正重要的东西。
原文:The human role. This is the one I keep coming back to. Defining work crisply enough that an agent can run for a day on it is harder than doing the work yourself. The skill that’s appreciating in value isn’t writing code. It’s writing specs that survive contact with an autonomous executor.
人类角色。 这是我反复回到的一个。把工作定义得足够清晰,清晰到能让一个 agent 跑一天 —— 这比你自己做这份工作还难。
原文金句:The skill that’s appreciating in value isn’t writing code. It’s writing specs that survive contact with an autonomous executor.
中译:正在升值的技能不是写代码。是写出能在和”自主执行器”接触后存活下来的 spec。
🟢 译者注:这句话是 Addy 全文最重要的一句话。未来工程师的稀缺技能不是 coding,是”撰写能让一个自主 agent 顺利完成一天工作的 spec”。这个技能更接近 PM、tech lead、staff engineer 的工作 —— 把模糊问题写成能被自主执行的规约。值得作为读完这篇的核心 takeaway。
这要去哪
原文:Google, Anthropic, and Cursor have converged on roughly the same shape. Separate the model loop from the execution sandbox from the durable session log. Split planning from generation from evaluation. Bake in compaction, hooks, and context resets. Expose memory as a managed service that any agent invocation can query.
Google、Anthropic、Cursor 大致汇聚到同一形状:
- 把 model loop / 执行 sandbox / 持久 session log 解耦
- 把规划 / 生成 / 评估拆开
- 把 compaction、hooks、context reset 烤进去
- 把 memory 暴露成 managed service,任何 agent 调用都可查询
原文:Surface area is what differs. Google’s Agent Platform is the enterprise-stack version, with the identity and audit trail story baked in. The patterns underneath are the same. Claude Managed Agents is “Anthropic’s harness, hosted.” Cursor’s background agents are “long-running coding, pulled out of the IDE and into the cloud.”
接触面才是各家的差别。Google 的 Agent Platform 是企业栈版本,身份和审计已就绪。底层模式是一样的。Claude Managed Agents 是 “Anthropic 的 harness,托管化”。Cursor 的 background agents 是 “把长跑编码从 IDE 里拉出来,放到云上”。
原文:The harder problems for the next year aren’t in any of those layers individually. They’re in the coordination above them. Many long-running agents on a shared codebase. Agents that read their own traces and patch their own harnesses. Harnesses that assemble tools and context just-in-time for a task instead of being pre-configured at startup. That’s where the agent stops looking like a smarter chat window and starts looking like a colleague who’s been on the project longer than you have.
接下来一年更难的问题,不在这些层各自里,而在它们之上的协调里:
- 很多长跑 agent 共用一个 codebase。
- agent 读自己的 trace、给自己 harness 打补丁。
- harness 按任务即时(just-in-time)组装工具和 context,而非启动时预先配好。
原文金句:That’s where the agent stops looking like a smarter chat window and starts looking like a colleague who’s been on the project longer than you have.
中译:这是 agent 不再像一个更聪明的聊天窗口、开始像一位”在这个项目上比你待得更久的同事”的拐点。
原文:The model is still load-bearing. But the gap between a chat window and an agent you can leave running overnight is mostly in the state, sessions, and structured handoffs wrapped around it. That’s where I’d spend my learning time right now.
模型仍然承重。但”聊天窗口”和”可以放着过夜的 agent”之间的鸿沟,绝大部分在围绕它的 state、session、结构化交接里。这就是我现在会把学习时间花在哪。
原文:If you want the prerequisite reading, my Agent Harness Engineering post covers the harness primitives this one builds on, and Self-improving agents goes deeper on the Ralph loop pattern.
如果你想要先修阅读,我的 Agent Harness Engineering 覆盖了本文构建于其上的 harness 原语;Self-improving agents 更深入讲 Ralph loop 模式。
译者总评
- 三堵墙是核心诊断框架:finite context / no persistent state / no self-verification。任何长跑 agent 设计都是对这三个问题的回答,看一个 agent 框架先看它怎么解这三件事。
- brain / hands / session 三分是三大厂(Anthropic / Cursor / Google)收敛出来的同一个架构形状。做生产级 agent,这是 default architecture,不是可选项。
- Ralph loop 100 行 bash 起步:在你考虑买 Anthropic Managed Agents 或 Google Agent Platform 之前,先用 bash + JSON + filesystem 把 Ralph loop 跑起来,体验”agent 失忆,filesystem 不失忆”的状态分离。这是最便宜的入门方式。
- 写 spec 的能力 > 写代码的能力:Addy 这句话(“The skill that’s appreciating in value isn’t writing code. It’s writing specs that survive contact with an autonomous executor.”)值得贴在工位上。当 agent 能跑 8 小时,你的瓶颈是定义”做完是什么样子”,不是写代码本身。
- memory drift 是 2026 年新出现的 ops 关切:agent 跨周积累记忆时,会从几次非典型互动学到错误的”流程捷径”,然后大规模应用。像治理 microservice 一样治理 memory —— Identity / Registry / Gateway / 审计日志全要有。这是把 agent 从 R&D 推到 production 的关键运维能力。
🔗 调研来源
- 原文: https://addyosmani.com/blog/long-running-agents/
- 配套精读: Addy Osmani 三连
- 配套全文: Agent Harness Engineering(全文)
- 相关原文: Anthropic — Effective harnesses for long-running agents
- 相关原文: Anthropic — Scaling Managed Agents: Decoupling the brain from the hands
- 相关原文: Anthropic — Long-running Claude (scientific computing)
- 相关原文: Cursor — Scaling long-running autonomous coding
- 相关原文: Google Cloud — Gemini Enterprise Agent Platform
- 相关原文: Geoffrey Huntley — Ralph
- 相关原文: METR — Time horizons
📝 配套精读 + 译者点评:Addy Osmani 三连